Dodd-Frank Act Stress Testing (DFAST) is now required also for smaller banks with assets less than $50 billion. Simply stated, the test requires a bank to assess possible losses in future years from the loans on the books. A report exploring many different future economic scenarios such as increases in the unemployment rates or short term interest rates must be submitted to the Federal Reserve.
A loan status evolves in time. A loan that is current can in the next period become delinquent and then in a future period it can default. A different scenario would be a loan transitioning from current to delinquent and then back to current. The modeling part consists of three major components:
1. Derive probabilities that a loan will transition from one state to another state in the next period. Clearly a loan can stay in the same state. The probabilities depend on many attributes of a loan.
2. With these transition probabilities derived, a Markov Chain model is set up. This model assesses the probability that a given loan would be default after a certain number of periods in the future (e.g., eight quarters).
3. The expected loss of a loan is its probability of default multiplied by the approximate loss.
The most challenging part is the derivation of the probabilities. On the paper this is an easy machine learning classification problem. Consider the case of current loans transitioning to delinquent. First, for each historical loan a set of attributes (features in the machine learning parlance) needs to be assembled. Candidates for features are the loan duration, location of the loan borrower, loan type, etc. Next, a subset of historical loans that transition from current to delinquent and a subset of loans that remain current are selected. The selected loans form the training data set. The third step is to set up models and lastly to evaluate them by using techniques such as 10-fold validation on a test data set.
Typical challenges of data sourcing and cleansing require a big chunk of the time. Several banks do not have enough historical data from their own operations and thus have to procure external data sets (and make sure that the loans on such external data sets resemble their loans).
The classification task at hand is to classify if a given loan is to become delinquent or not in the next time period. As such it is a textbook binary classification problem. There are two hidden challenges. The first one is that the training set is heavily imbalanced since many more loans stay current than transition to delinquent. It is known that in such cases special techniques must be employed. Equally important is the fact that there are many possible features, in excess to one hundred.
We have been engaged in a few DFAST related projects and have faced the feature selection challenge. We started with standard techniques of the principle component analysis (PCA) or information gain (the so-called maximum relevancy minimum redundancy algorithm). Either technique reduced the feature space and then classification models (logistic regression, support vector machine, random forests) were evaluated.
We tackled a few problems requiring deep learning which is a technique well suited for complex problems. While the DFAST problem is not as complex as, for example, recognizing from an image if a passenger is to cross a road, we decided to try the Restricted Boltzmann Machine (RBM) as a technique to reduce the feature space. In RBM, an input (visible) vector is fed to the model, then it is mapped through the notion of the energy function into a lower dimensional hidden vector which is then lifted back to the original space of the feature vector. The goal is to tune parameters (b’,c’,W) in the energy function so that the recovered vector in probability comes close to the original vector.
A loan status evolves in time. A loan that is current can in the next period become delinquent and then in a future period it can default. A different scenario would be a loan transitioning from current to delinquent and then back to current. The modeling part consists of three major components:
1. Derive probabilities that a loan will transition from one state to another state in the next period. Clearly a loan can stay in the same state. The probabilities depend on many attributes of a loan.
2. With these transition probabilities derived, a Markov Chain model is set up. This model assesses the probability that a given loan would be default after a certain number of periods in the future (e.g., eight quarters).
3. The expected loss of a loan is its probability of default multiplied by the approximate loss.
The most challenging part is the derivation of the probabilities. On the paper this is an easy machine learning classification problem. Consider the case of current loans transitioning to delinquent. First, for each historical loan a set of attributes (features in the machine learning parlance) needs to be assembled. Candidates for features are the loan duration, location of the loan borrower, loan type, etc. Next, a subset of historical loans that transition from current to delinquent and a subset of loans that remain current are selected. The selected loans form the training data set. The third step is to set up models and lastly to evaluate them by using techniques such as 10-fold validation on a test data set.
Typical challenges of data sourcing and cleansing require a big chunk of the time. Several banks do not have enough historical data from their own operations and thus have to procure external data sets (and make sure that the loans on such external data sets resemble their loans).
The classification task at hand is to classify if a given loan is to become delinquent or not in the next time period. As such it is a textbook binary classification problem. There are two hidden challenges. The first one is that the training set is heavily imbalanced since many more loans stay current than transition to delinquent. It is known that in such cases special techniques must be employed. Equally important is the fact that there are many possible features, in excess to one hundred.
We have been engaged in a few DFAST related projects and have faced the feature selection challenge. We started with standard techniques of the principle component analysis (PCA) or information gain (the so-called maximum relevancy minimum redundancy algorithm). Either technique reduced the feature space and then classification models (logistic regression, support vector machine, random forests) were evaluated.
We tackled a few problems requiring deep learning which is a technique well suited for complex problems. While the DFAST problem is not as complex as, for example, recognizing from an image if a passenger is to cross a road, we decided to try the Restricted Boltzmann Machine (RBM) as a technique to reduce the feature space. In RBM, an input (visible) vector is fed to the model, then it is mapped through the notion of the energy function into a lower dimensional hidden vector which is then lifted back to the original space of the feature vector. The goal is to tune parameters (b’,c’,W) in the energy function so that the recovered vector in probability comes close to the original vector.
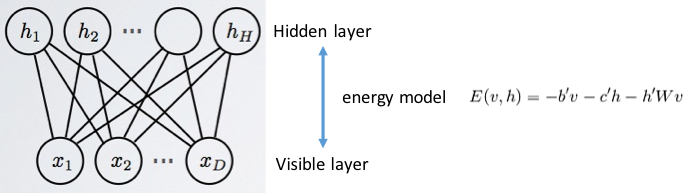
The entire classification is then performed by having an input vector, then based on RBM calculating the hidden vector which is then classified into delinquent or not. [This flow actually follows the paradigm of deep belief networks which typically include more than one hidden layer.]
To our surprise, the RBM based classification model outperforms the vast variety of other traditional feature selection and classification models. The improvement was drastic, the F1 score jumped from 0.13 to 0.5. This was a very nice ‘exercise’ that is hard to push to end users which have heard of logistic regression and PCA and might even know how they work, but would be very uncomfortable using something that is called RBM (but would be much more receptive if the acronym means role-based management).
To our surprise, the RBM based classification model outperforms the vast variety of other traditional feature selection and classification models. The improvement was drastic, the F1 score jumped from 0.13 to 0.5. This was a very nice ‘exercise’ that is hard to push to end users which have heard of logistic regression and PCA and might even know how they work, but would be very uncomfortable using something that is called RBM (but would be much more receptive if the acronym means role-based management).
 RSS Feed
RSS Feed