Author
Jie Yang, Ph.D candidate in Civil and Environmental Engineering, Northwestern University
[email protected]
More and more airlines are putting emphasis on “merchandizing.” But aren’t they doing this right now? Unfortunately, most of them are not. Traditional carriers rely on their complex distribution channels and most of their focus is on managing those channels such as OTAs, off-line travel agencies, etc. Selling through direct channel is lucrative yet most airlines are in their early stage. As one part of merchandising capability, personalization heavily relies on airlines’ understanding of their travelers’ data and the ability to collect data. That is also why more and more airlines are trying to bring their travelers to their own website and complete the booking.
This trend however may disrupt current market ecosystem where global distribution system (GDS) sells the majority of fares. To prevent airlines’ corner overtaking strategies, GDS has to take some actions! Comparing to airlines’ database, GDS companies’ competitive advantage is that they have data from all different airlines who use GDS. Most importantly, some GDS companies have the ability to “shop-back” and match bookings with the itineraries displayed to travelers. But this process is computationally expensive. So, an interesting problem came to our mind that can we use unmatched itineraries (i.e. unlabeled data or data without observed label) to improve airlines’ understanding of a potential market?
Airlines can understand a market such as Chicago to Shanghai from different aspects. To predict their market share, they use discrete choice model and the basic one (i.e. multinomial logit model) assumes a traveler’s utility or impression on an itinerary is given by a linear function of weighted features plus a gumbel noise. The goal of this model is to predict probability of choosing one itinerary. And it can also be used to estimate an airline’s market share or to estimate a traveler’s preferred rank of returned itineraries. In a typical case, to estimate such a model we need to know choice sets and also booked itineraries within each set. But those unlabeled choice sets may also be used as a way to improve the typical model estimation.
How can we utilize those choice sets? There were lots of research focusing on improving classification model estimation with unlabeled data. So it is worthwhile to try similar algorithms onto our problem. Inspired by this, we adapted four different algorithms. Three of them were based on clustering methods while another one was based on expectation-maximization algorithm. To evaluate the methods, we designed cross-validation experiments based on a public hotel dataset and compared the prediction accuracy. Results are presented below. We gradually increase the percentage of booked data with respect to unlabeled data. The metric we used is based on Kendall’s tau and model used was based on a ranked-logit choice model. For this metric, the lower the better. And we can see the zero Y-axis is the baseline which is the prediction provided by a model we estimated with only booked data. It is clear that our algorithms have a better performance than the baseline model for up to 10%.
This trend however may disrupt current market ecosystem where global distribution system (GDS) sells the majority of fares. To prevent airlines’ corner overtaking strategies, GDS has to take some actions! Comparing to airlines’ database, GDS companies’ competitive advantage is that they have data from all different airlines who use GDS. Most importantly, some GDS companies have the ability to “shop-back” and match bookings with the itineraries displayed to travelers. But this process is computationally expensive. So, an interesting problem came to our mind that can we use unmatched itineraries (i.e. unlabeled data or data without observed label) to improve airlines’ understanding of a potential market?
Airlines can understand a market such as Chicago to Shanghai from different aspects. To predict their market share, they use discrete choice model and the basic one (i.e. multinomial logit model) assumes a traveler’s utility or impression on an itinerary is given by a linear function of weighted features plus a gumbel noise. The goal of this model is to predict probability of choosing one itinerary. And it can also be used to estimate an airline’s market share or to estimate a traveler’s preferred rank of returned itineraries. In a typical case, to estimate such a model we need to know choice sets and also booked itineraries within each set. But those unlabeled choice sets may also be used as a way to improve the typical model estimation.
How can we utilize those choice sets? There were lots of research focusing on improving classification model estimation with unlabeled data. So it is worthwhile to try similar algorithms onto our problem. Inspired by this, we adapted four different algorithms. Three of them were based on clustering methods while another one was based on expectation-maximization algorithm. To evaluate the methods, we designed cross-validation experiments based on a public hotel dataset and compared the prediction accuracy. Results are presented below. We gradually increase the percentage of booked data with respect to unlabeled data. The metric we used is based on Kendall’s tau and model used was based on a ranked-logit choice model. For this metric, the lower the better. And we can see the zero Y-axis is the baseline which is the prediction provided by a model we estimated with only booked data. It is clear that our algorithms have a better performance than the baseline model for up to 10%.
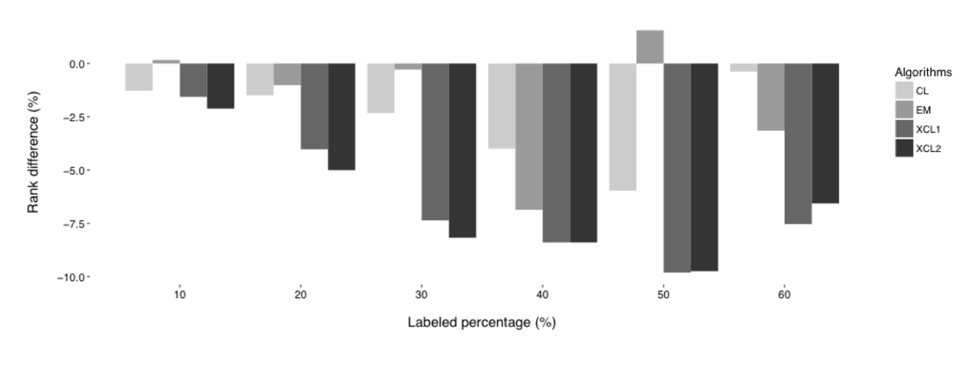
Specifically, we applied clustering-and-label (CL), expectation maximization (EM), x-clustering-and-label-1 (XCL1) and x-clustering-and-label-2 (XCL2). XCL1 and XCL2 are advanced clustering methods which explores the clustering structure automatically without setting a target number. It indicates that XCL1 and XCL2 are better than the other two algorithms.
In all, we believe this research may benefit GDS companies to provide better solutions to airlines, especially those non-legacy carriers who have not the capability to build up its own channel or IT infrastructure.
In all, we believe this research may benefit GDS companies to provide better solutions to airlines, especially those non-legacy carriers who have not the capability to build up its own channel or IT infrastructure.
 RSS Feed
RSS Feed