There are many start-ups screaming Data Science as a Service (DSaaS). The shortage of data scientists is well document and thus DSaaS makes sense. However, data science is complex and steps such as feature engineering and hyper parameter tuning are tough nuts to crack.
There are several feature selection algorithms with varying degree of success and adoption, but feature selection is different from feature creation which often requires domain expertise. Given a set of features, feature selection can be automated, but the latter is still unsolvable without substantial human involvement and interaction.
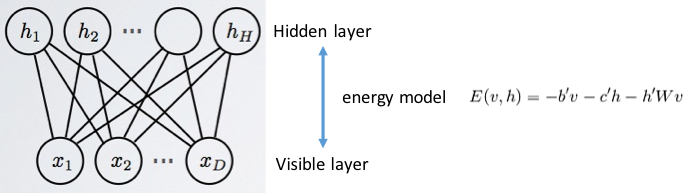
On the surface hyper parameter tuning and model construction are further down the automation and self-service path thanks to the abundant research work and commercial offerings of autoML. Scholars and industry researchers have developed many algorithms for autoML with two prevailing approaches of Bayesian optimization and reinforcement learning. Training of a new configuration can now be aborted early and perhaps restarted later if other attempts are not as promising as the first indicators were showing. Training of a new configuration has also been improved by exploiting previously obtained weights. In short, given a particular and unique image problem autoML can without human assistance configure a CNN-like network together with all other hyper-parameters (optimization algorithm, mini-batch size, etc). Indeed, autoML is able to construct novel architectures that compete and even outperform hand-crafted architectures and to create brand new activation functions.
Google’s autoML which is part of their Google Cloud Platform have competed in Kaggle’s competitions. On older competitions autoML would have always been in top ten. In a recent competition autoML competed ‘live’ and finished second. This attests that automatic hyper parameter tuning can compete with best humans.
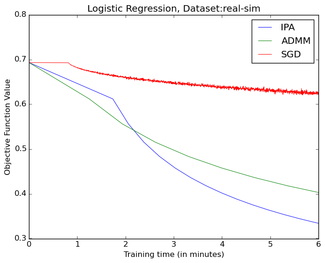
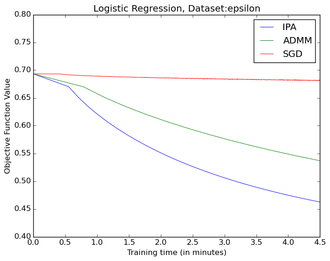
There is one important aspect left out. autoML requires substantial computing resources. On deep learning problems it often requires weeks and even months of computing time on thousands of GPUs. There are not many companies that can afford such expenses on a single AI business problem. Even Fortune 500 companies that we collaborate with are reluctant to go down this path. If organizations with billions of quarterly revenue cannot make a business case for autoML, then it is obvious that scholars in academia cannot conduct research in this area. We can always work on toy problems, but this would take us only so far. The impact would be limited due to unknown scalability of proposed solutions and publishing work on limited computational experiments would be hindered. A recent PhD student of mine recently stated “I do not want to work on an autoML project since we cannot compete with Google due to computational resources.” This says a lot.
The implication is that autoML is going to continue to be further developed only by experts in tech giants who already have in place computational resources. Most if not all of the research will be left out of academia. This does not imply that autoML is doomed since in AI it is easy to argue that research in industry is ahead of academic contributions. However, it does imply that the progress is going to be slower since only one party is going to drive the agenda. On the positive side, Amazon, Google, and Microsoft have a keen interest in improving their autoML solutions as part of their cloud platforms. It can be an important differentiation factor driving customers.
Before autoML becomes more used in industry, the computational requirements must be lowered, and this is possible only with further research. I guess we are at the mercy of FAANG (like we are for many other aspects outside autoML) to make autoML more affordable.
There are several feature selection algorithms with varying degree of success and adoption, but feature selection is different from feature creation which often requires domain expertise. Given a set of features, feature selection can be automated, but the latter is still unsolvable without substantial human involvement and interaction.
On the surface hyper parameter tuning and model construction are further down the automation and self-service path thanks to the abundant research work and commercial offerings of autoML. Scholars and industry researchers have developed many algorithms for autoML with two prevailing approaches of Bayesian optimization and reinforcement learning. Training of a new configuration can now be aborted early and perhaps restarted later if other attempts are not as promising as the first indicators were showing. Training of a new configuration has also been improved by exploiting previously obtained weights. In short, given a particular and unique image problem autoML can without human assistance configure a CNN-like network together with all other hyper-parameters (optimization algorithm, mini-batch size, etc). Indeed, autoML is able to construct novel architectures that compete and even outperform hand-crafted architectures and to create brand new activation functions.
Google’s autoML which is part of their Google Cloud Platform have competed in Kaggle’s competitions. On older competitions autoML would have always been in top ten. In a recent competition autoML competed ‘live’ and finished second. This attests that automatic hyper parameter tuning can compete with best humans.
There is one important aspect left out. autoML requires substantial computing resources. On deep learning problems it often requires weeks and even months of computing time on thousands of GPUs. There are not many companies that can afford such expenses on a single AI business problem. Even Fortune 500 companies that we collaborate with are reluctant to go down this path. If organizations with billions of quarterly revenue cannot make a business case for autoML, then it is obvious that scholars in academia cannot conduct research in this area. We can always work on toy problems, but this would take us only so far. The impact would be limited due to unknown scalability of proposed solutions and publishing work on limited computational experiments would be hindered. A recent PhD student of mine recently stated “I do not want to work on an autoML project since we cannot compete with Google due to computational resources.” This says a lot.
The implication is that autoML is going to continue to be further developed only by experts in tech giants who already have in place computational resources. Most if not all of the research will be left out of academia. This does not imply that autoML is doomed since in AI it is easy to argue that research in industry is ahead of academic contributions. However, it does imply that the progress is going to be slower since only one party is going to drive the agenda. On the positive side, Amazon, Google, and Microsoft have a keen interest in improving their autoML solutions as part of their cloud platforms. It can be an important differentiation factor driving customers.
Before autoML becomes more used in industry, the computational requirements must be lowered, and this is possible only with further research. I guess we are at the mercy of FAANG (like we are for many other aspects outside autoML) to make autoML more affordable.
 RSS Feed
RSS Feed