One of the biggest hustles in mapreduce is model calibration for machine learning models such as the logistic regression and SVM. These algorithms are based on gradient optimization and require iterative computations of the gradient and in turn updating the weights. Mapreduce is ill suited for this since in each iteration the data has to be read from hdfs and there is significant cost of starting and winding down a mapreduce job.
On the other hand, Spark with its capability to persist rdd’s (resilient distributed dataset) in memory and natively offering dataflow capabilities, is a great candidate for efficient calibration on rdd’s.
Gradient based algorithms on distributed data sets rely on the paradigm of solving the optimization problem on each partition and then combining the solutions together. We implemented in scala three algorithms.
1. Iterative parameter averaging (IPA): On each partition a single pass of the standard gradient algorithm is performed which produces weights. Weights from each partition are then averaged and form the initial weights for the next pass. The pseudo code is provided below.
Initialize w
Loop
Broadcast w to each partition
weightRDD = For each partition in rdd inputData
wp = w
Perform a single gradient descent pass over the records in
the partition by iteratively updating wp
Return wp
/* weightRDD is the rdd storing new weights */
w = average of all weights in weightRDD
Return w
The key is to keep the rdd inputData in memory (persist before calling IPA).
2. Alternating direction method of multipliers (ADMM): http://stanford.edu/~boyd/admm.html
This method is based on the concept of the augmented Lagrangian. In each iteration for each partition the calibration model is solved on the records pertaining to the partition. The objective function is altered and it consists of the standard loss and a penalty term driving the weights to resemble the average weights. One needs to solve an extra regularization problem with penalties. For L2 and L1 norms this problem has a closed form solution.
After each partition computes its weights, they are averaged and the penalty term adjusted. Each partition has its own set of weights.
Since the algorithm is complex, we do not provide the pseudo code. The bulk of the pseudo code is actually very similar to IPA, however there is additional work performed by the driver.
One challenge, i.e., inefficiency in spark or ‘we do not how to do it in spark,’ is the inability in spark to send particular data (in our case the penalties) to a particular actor working on a partition. Instead we had to do a forecast to all actors and then during processing of a partition only the relevant penalties that have been broadcast are used. The main issue here is that all penalties for each partition has to be held in memory at the driver. For very large-scale rdd’s with many features this will be a bottleneck.
3. Progressive hedging (PH): This is very similar to ADMM. The regularization subproblem has a different from than in ADMM, but it still exhibits closed form solutions for L2 and L1 norms.
The implementations together with test codes are available at https://github.com/wxhC3SC6OPm8M1HXboMy/spark-ml-optimization
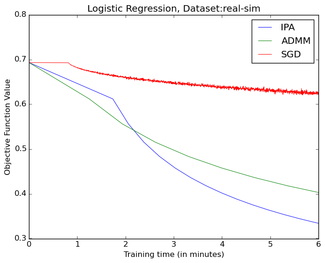
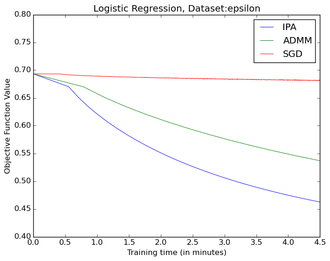
Below is a comparison with Spark on 4 CPUs each one with 8 cores for two large data sets. IPA is a clear winner with the default spark SGD being the worst algorithm.
On the other hand, Spark with its capability to persist rdd’s (resilient distributed dataset) in memory and natively offering dataflow capabilities, is a great candidate for efficient calibration on rdd’s.
Gradient based algorithms on distributed data sets rely on the paradigm of solving the optimization problem on each partition and then combining the solutions together. We implemented in scala three algorithms.
1. Iterative parameter averaging (IPA): On each partition a single pass of the standard gradient algorithm is performed which produces weights. Weights from each partition are then averaged and form the initial weights for the next pass. The pseudo code is provided below.
Initialize w
Loop
Broadcast w to each partition
weightRDD = For each partition in rdd inputData
wp = w
Perform a single gradient descent pass over the records in
the partition by iteratively updating wp
Return wp
/* weightRDD is the rdd storing new weights */
w = average of all weights in weightRDD
Return w
The key is to keep the rdd inputData in memory (persist before calling IPA).
2. Alternating direction method of multipliers (ADMM): http://stanford.edu/~boyd/admm.html
This method is based on the concept of the augmented Lagrangian. In each iteration for each partition the calibration model is solved on the records pertaining to the partition. The objective function is altered and it consists of the standard loss and a penalty term driving the weights to resemble the average weights. One needs to solve an extra regularization problem with penalties. For L2 and L1 norms this problem has a closed form solution.
After each partition computes its weights, they are averaged and the penalty term adjusted. Each partition has its own set of weights.
Since the algorithm is complex, we do not provide the pseudo code. The bulk of the pseudo code is actually very similar to IPA, however there is additional work performed by the driver.
One challenge, i.e., inefficiency in spark or ‘we do not how to do it in spark,’ is the inability in spark to send particular data (in our case the penalties) to a particular actor working on a partition. Instead we had to do a forecast to all actors and then during processing of a partition only the relevant penalties that have been broadcast are used. The main issue here is that all penalties for each partition has to be held in memory at the driver. For very large-scale rdd’s with many features this will be a bottleneck.
3. Progressive hedging (PH): This is very similar to ADMM. The regularization subproblem has a different from than in ADMM, but it still exhibits closed form solutions for L2 and L1 norms.
The implementations together with test codes are available at https://github.com/wxhC3SC6OPm8M1HXboMy/spark-ml-optimization
Below is a comparison with Spark on 4 CPUs each one with 8 cores for two large data sets. IPA is a clear winner with the default spark SGD being the worst algorithm.
 RSS Feed
RSS Feed