Author
XIaofeng Zhu, PhD candidate in Electrical Engineering and Computer Science, Northwestern University
[email protected]
Most of the existing ontologies such as DBpedia rely on supervised ontology learning via manual parsing or transferring from existing knowledge bases. However, knowledge-bases in some specific domains such as semiconductor packaging do not exist, and supervised ontology learning is not appropriate for learning ontologies in new domains. In contrast, unsupervised ontology learning which is generally based on topic modeling can learn new entities and their relations from plain text and is likely to perform better when having more data. In this post, we will show you how to learn a terminological ontology in a specific domain via hrLDA.
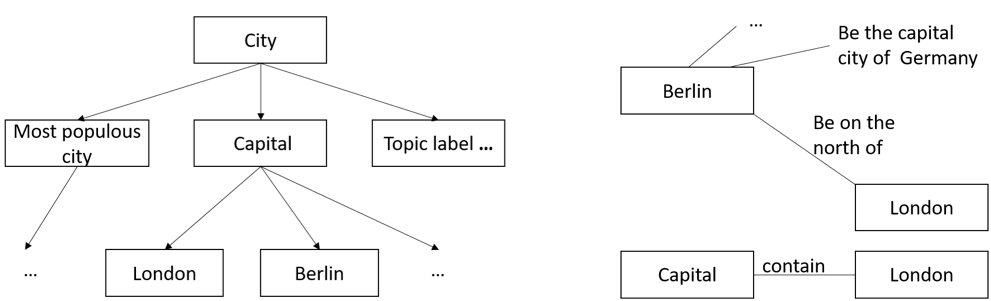
Among all types of ontologies, our work focuses on terminological ontologies. In short, a terminological ontology is a hierarchical structure of subject-verb-object triplets (illustrated in below figure). Before we explain the concept terminological ontology, we need to talk about what a topic is. A topic is a list of words with different probabilities being in this topic, which is the fundamental assumption of Latent Dirichlet Allocation (LDA). A topic label is noun phrase and also a node in a topic tree, for example, city or London. A topic path is a list of topic labels from the root to one leaf. A terminological ontology has two components: topic hierarchies in a topic tree (shown on the left side) and topic relations between any two topic labels (shown on the right side). Capital is a sub-concept of city. Be on the north of is the relationship between Berlin and London. We use hierarchical topic modeling to extract topic hierarchies and we use relation extraction to extract topic relations.
Among all types of ontologies, our work focuses on terminological ontologies. In short, a terminological ontology is a hierarchical structure of subject-verb-object triplets (illustrated in below figure). Before we explain the concept terminological ontology, we need to talk about what a topic is. A topic is a list of words with different probabilities being in this topic, which is the fundamental assumption of Latent Dirichlet Allocation (LDA). A topic label is noun phrase and also a node in a topic tree, for example, city or London. A topic path is a list of topic labels from the root to one leaf. A terminological ontology has two components: topic hierarchies in a topic tree (shown on the left side) and topic relations between any two topic labels (shown on the right side). Capital is a sub-concept of city. Be on the north of is the relationship between Berlin and London. We use hierarchical topic modeling to extract topic hierarchies and we use relation extraction to extract topic relations.
hrLDA builds on hierarchical latent Dirichlet allocation (hLDA) and overcomes its limitations. The four components of hrLDA are relation-based latent Dirichlet allocation (rLDA), relation triplet extraction, acquaintance Chinese restaurant process (ACRP), and nested acquaintance Chinese restaurant process.
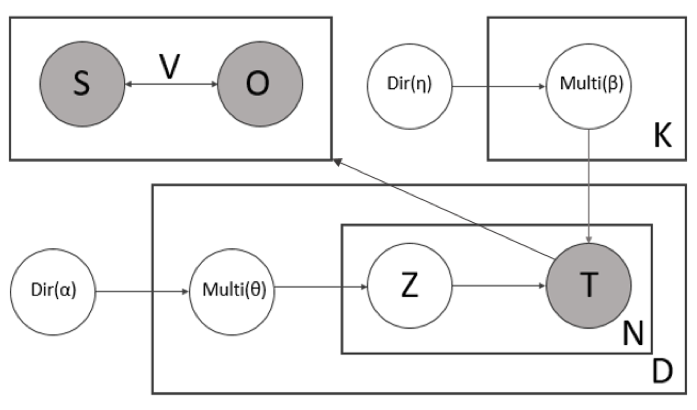
Relation-based Latent Dirichlet Allocation: Relation-based Latent Dirichlet AllocationIn contrast to LDA, rLDA takes a document as a bag of subject-verb-object triplets with the subject nouns as keys. In this way, we give salient nouns (nouns having more relation triplets) high weights. The other difference is that the number of topics in rLDA is computed by ACRP instead of a hyper-parameter. The figure below illustrates the plate notation of rLDA for extracting K topics from Corpus D having N documents. T is the list of subject-verb-object (S-V-O) relation triplets in a document. Z represents the topic assignments for the relation triplets. Multi(\beta) and Multi(\theta) are multinomial topic-word distribution and multinomial document-topic distributions. Dir(\alpha) and Dir(\eta) are hyper-parameters.
Relation-based Latent Dirichlet Allocation: Relation-based Latent Dirichlet AllocationIn contrast to LDA, rLDA takes a document as a bag of subject-verb-object triplets with the subject nouns as keys. In this way, we give salient nouns (nouns having more relation triplets) high weights. The other difference is that the number of topics in rLDA is computed by ACRP instead of a hyper-parameter. The figure below illustrates the plate notation of rLDA for extracting K topics from Corpus D having N documents. T is the list of subject-verb-object (S-V-O) relation triplets in a document. Z represents the topic assignments for the relation triplets. Multi(\beta) and Multi(\theta) are multinomial topic-word distribution and multinomial document-topic distributions. Dir(\alpha) and Dir(\eta) are hyper-parameters.
Relation Triple Extraction: The extracted relation triplets can be classified as three types. The first type: subject-predicate-object-based relations are relations that can be extracted using Stanford NLP parser and Ollie relation extraction library. The second type: noun-based/hidden relations are relations that reside in compound nouns and acronyms. The third type: relations from document structures. For instance, the indentation and bullet types of this slide indicate relations. hrLDA finds the topic numbers via a partition method ACRP.
Acquaintance Chinese Restaurant Process: A noun phrase has four properties: content, (paragraph, sentence) coordinates, one-to-many relation triplets and document ID. People tend to put phrases that describe the same topic together. Visually phrases that are close to each other regarding (paragraph, sentence) coordinates are acquaintances. Equation 1-5 shows the probability of noun phrase (n+1) choosing its topic id from [1 … k+1], which models how people order their wording when they write documents. \eta is a small hyper-parameter. C_i is the number of noun phrases joining topic i. Q_{1:i} represents paragraph location differences, and S_{1:i} represents sentence location differences. When people write one document, the probability of forming a new topic if there are non-empty topics is small, the same topic that has the same content words is close to 1, not likely to join the topic that does not have any acquaintances. Words appear in the same paragraph are close acquaintances if they are even closer if in the same sentence. It is true that this it not optimal yet, but a big improvement over the Chinese restaurant process (CRP) in hLDA.
Acquaintance Chinese Restaurant Process: A noun phrase has four properties: content, (paragraph, sentence) coordinates, one-to-many relation triplets and document ID. People tend to put phrases that describe the same topic together. Visually phrases that are close to each other regarding (paragraph, sentence) coordinates are acquaintances. Equation 1-5 shows the probability of noun phrase (n+1) choosing its topic id from [1 … k+1], which models how people order their wording when they write documents. \eta is a small hyper-parameter. C_i is the number of noun phrases joining topic i. Q_{1:i} represents paragraph location differences, and S_{1:i} represents sentence location differences. When people write one document, the probability of forming a new topic if there are non-empty topics is small, the same topic that has the same content words is close to 1, not likely to join the topic that does not have any acquaintances. Words appear in the same paragraph are close acquaintances if they are even closer if in the same sentence. It is true that this it not optimal yet, but a big improvement over the Chinese restaurant process (CRP) in hLDA.
The probability of choosing the $(k + 1)^{th}$ topic reads \[P(z_{n+1} = (k+1) | Z_{1:n}) = \frac{\gamma}{n+ \gamma}.\]
The probability of selecting any of the $k$ topics is
- if the content of $t^{n+1}$ is synonymous with or an acronym of a previously analyzed noun phrase $t^m$ $(m < n +1)$ in the $i^{th}$ topic, \[P(z_{n+1} = i | Z_{1:n}) = 1 - \gamma;\]
- else if the document ID of $t^{n+1}$ is different from all document IDs belonging to the $i^{th}$ topic, \[P(z_{n+1} = i | Z_{1:n}) = \gamma;\] \[P(z_{n+1} = i | Z_{1:n}) = \] \[\frac{C_i - (1 - \frac{1}{min(Q_{1:i})})}{(1 + min(S_{1:i})) n+ \gamma},\]
-
Nested Acquaintance Chinese Restaurant Process: A topic tree is generated via recursively applying rLDA and ACRP in a top-down fashion. For instance, we start with all the noun phrases at level 0 Node 1. We use ACRP to calculate the topic number K^0_1 at level 0 from Node 1 and the initial state of rLDA. We then apply rLDA to get the actual topic distribution and keep the top phrases as topic labels. Next, we remove the topic labels and feed the unpartitioned noun phrases to ACRP and rLDA until all the phrases are assigned as topic labels. Connecting all the topic labels colored in read, we get a topic tree. After we link the relation triplets back to the noun phrases we get a terminological ontology.
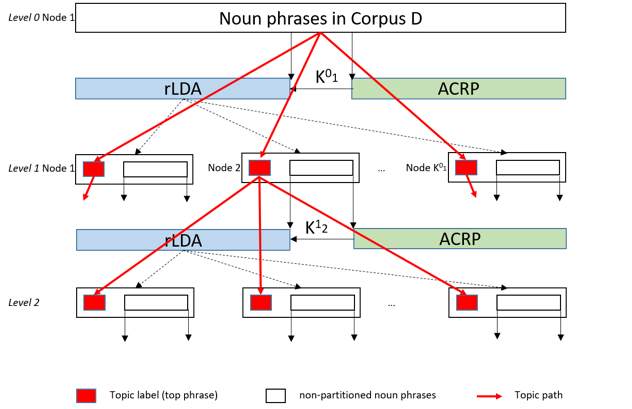
Empirical Results: A unique advantage of hrLDA is that it is not sensitive to messy/noisy text that is about multiple domains. For instance, the input text is about four domains: Semiconductor, Integrated circuit, Berlin and London. hrLDA can create four big branches for the four domains. However, hLDA mixes words from different domains into the same topic because LDA is applied vertically and each document is only allowed to have one topic path. More empirical results and analysis can be found in out paper. The code and data is available on GitHub.

 RSS Feed
RSS Feed