Author
Papis Wongchaisuwat, Ph.D candidate in Industrial Engineering and Management Sciences, Northwestern University
[email protected]
While large number of internet users seek health information online, it is not trivial for them to quickly find an accurate answer to specific questions. Community-based Question Answering (CQA) sites such as Yahoo! Answers play an important role in addressing health information needs. In CQA sites, users post a question and expect the online health community to promptly provide desirable answers. Despite a high volume of users’ participation, a considerable number of questions are left unanswered and at the same time other questions that address the same information need are answered elsewhere. Automatically answering the posted questions can provide a useful source of information for online health communities.
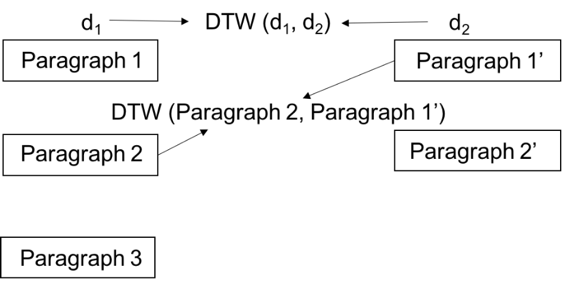
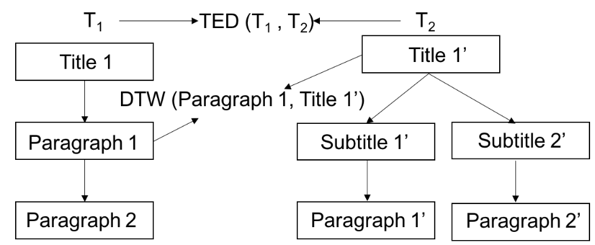
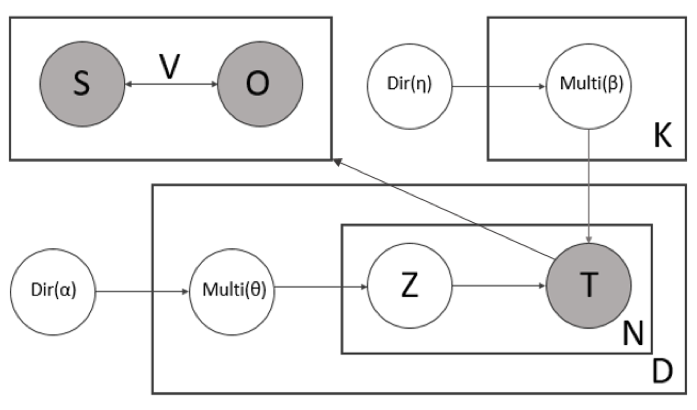
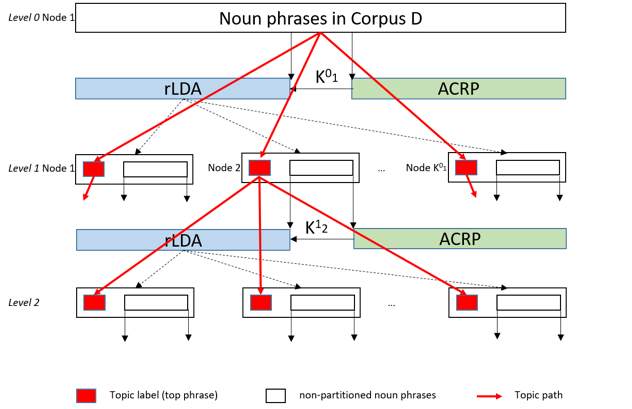
We developed a 2-phase algorithm to automatically answer health-related questions based on past questions and answers (QA). Our proposed algorithm uses information retrieval techniques to identify candidate answers from resolved QA and further re-rank these candidates with a semi-supervised leaning algorithm that extracts the best answer to a prospective question. We first converts the raw data into a desirable structure which is collected as a corpus of existing QA pairs. The first phase implemented as a rule-based system that employs similarity measures, i.e. Dynamic Time Warping (DTW), and vector-space based approach (VS) to find candidate answers from the corpus of existing QA pairs for any prospective question. In the second phase, we implemented supervised and Expectation Maximization (EM) based semi-supervised learning models that refined the output of the first phase by screening out invalid answers and ranking the remaining valid answers.
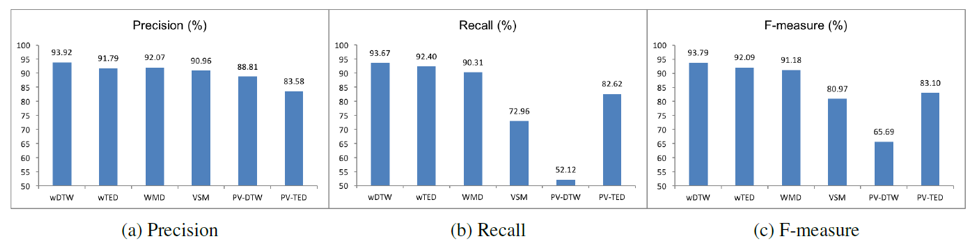
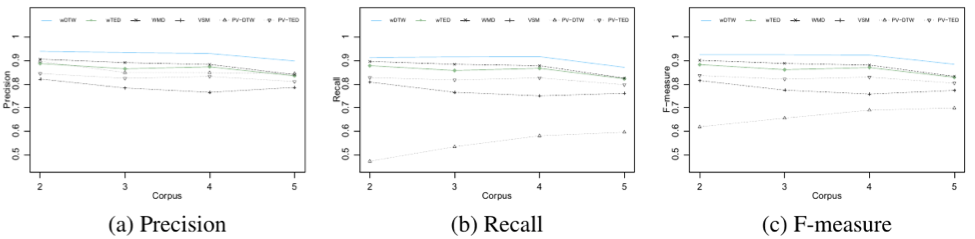
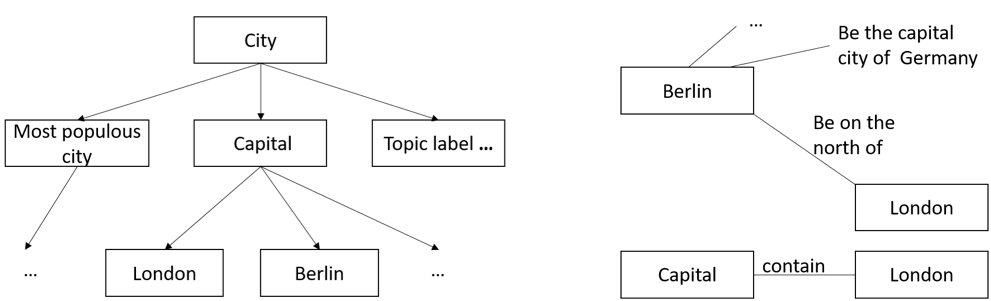
We obtained a total of 4,216 alcoholism-related QA threads from Yahoo! Answers as a case study. Based on our dataset, the semi-supervised learning algorithm has an accuracy of 86.2%. UMLS-based (health-related) features used in the model enhance the algorithm’s performance by proximately 8 %. An example result returned from the algorithm to determine candidate answers is shown in the figure below.
We developed a 2-phase algorithm to automatically answer health-related questions based on past questions and answers (QA). Our proposed algorithm uses information retrieval techniques to identify candidate answers from resolved QA and further re-rank these candidates with a semi-supervised leaning algorithm that extracts the best answer to a prospective question. We first converts the raw data into a desirable structure which is collected as a corpus of existing QA pairs. The first phase implemented as a rule-based system that employs similarity measures, i.e. Dynamic Time Warping (DTW), and vector-space based approach (VS) to find candidate answers from the corpus of existing QA pairs for any prospective question. In the second phase, we implemented supervised and Expectation Maximization (EM) based semi-supervised learning models that refined the output of the first phase by screening out invalid answers and ranking the remaining valid answers.
We obtained a total of 4,216 alcoholism-related QA threads from Yahoo! Answers as a case study. Based on our dataset, the semi-supervised learning algorithm has an accuracy of 86.2%. UMLS-based (health-related) features used in the model enhance the algorithm’s performance by proximately 8 %. An example result returned from the algorithm to determine candidate answers is shown in the figure below.


 RSS Feed
RSS Feed