Author
XIaofeng Zhu, PhD candidate in Electrical Engineering and Computer Science, Northwestern University
[email protected]
I went to the bank” is semantically more similar to “I withdrew some money.” than “I went to the park.” However, most widely used distance measures think the later sentence is more similar because the later sentence has more common words. In this post, we will explain two new algorithms - word vector-based dynamic time warping (wDTW) and word vector-based tree edit distance (wTED) - for measuring semantic document distances based on distributed representations of words. Both algorithms hinge on the distance between two paragraphs and are implemented in Apache Spark. We train word2vec vectors beforehand and represent a document as a list of paragraphs where a paragraph is a list of word2vec vectors.
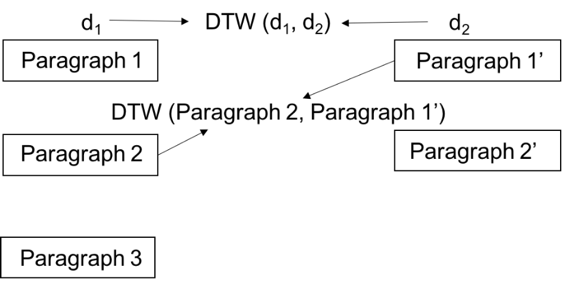
DTW measures the distance between two sequences: wDTW algorithm calculates document distances based on DTW by sequentially comparing any two paragraphs of two documents. The figure below demonstrates how wDTW finds the optimal alignments between two documents.
DTW measures the distance between two sequences: wDTW algorithm calculates document distances based on DTW by sequentially comparing any two paragraphs of two documents. The figure below demonstrates how wDTW finds the optimal alignments between two documents.
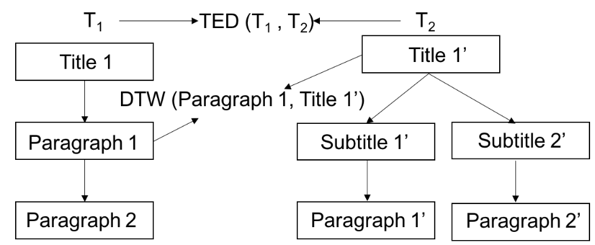
Word Vector-based Tree Edit Distance (wTED): Word Vector-based Tree Edit Distance (wTED)TED calculates the minimal cost of node edit operations for transforming one labeled tree into another. A document can be viewed at multiple abstraction levels that include the document title, its sections, subsections, etc. The next figure illustrates wTED distance between two document trees.
Document Revision Detection: We used wDTW and wTED to solve a document revision detection problem by taking a document as an arc in a revision network and the distance score of two documents as the arc length. We conclude that the revision of a document is the document that has the smallest distance score based on the minimal branching algorithm. We next report the performance of our semantic measures on two types of data sets.
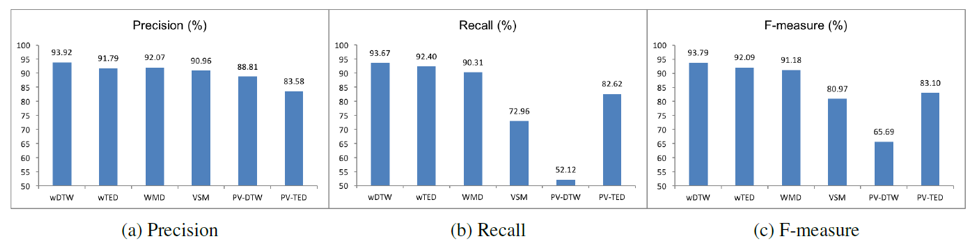
Distance/Similarity Measures: We compared our measures wDTW and wTED with four baselines: Vector Space Model (VSM), Word Mover Distance (WMD), PV-DTW(Paragraph vector + DTW), and PV-TED (Paragraph vector + TED).
Data Sets
Distance/Similarity Measures: We compared our measures wDTW and wTED with four baselines: Vector Space Model (VSM), Word Mover Distance (WMD), PV-DTW(Paragraph vector + DTW), and PV-TED (Paragraph vector + TED).
Data Sets
- Wikipedia Revision Dumps (long, linear revisions)
- Simulated Data sets (short, tree revisions): Insertion, deletion, and substation of words, paragraphs, and titles
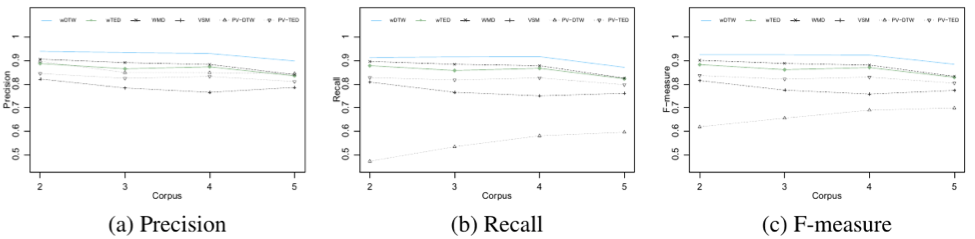
Performance on the Simulated Data Sets
Findings
wDTW consistently performs the best. WMD is better than wTED.
wDTW consistently performs the best. WMD is better than wTED.
- The performances of wDTW and wTED drop slower than others.
- wDTW and wTED use dynamic programming to find the global optimal alignment.
- WMD relies on a greedy algorithm that sums up the minimal cost for every word.
- Paragraph distance using word2vec is more accurate than using paragraph vectors.
 RSS Feed
RSS Feed